Variables used in operators need to be configured in advance during task development.
Data Input Node
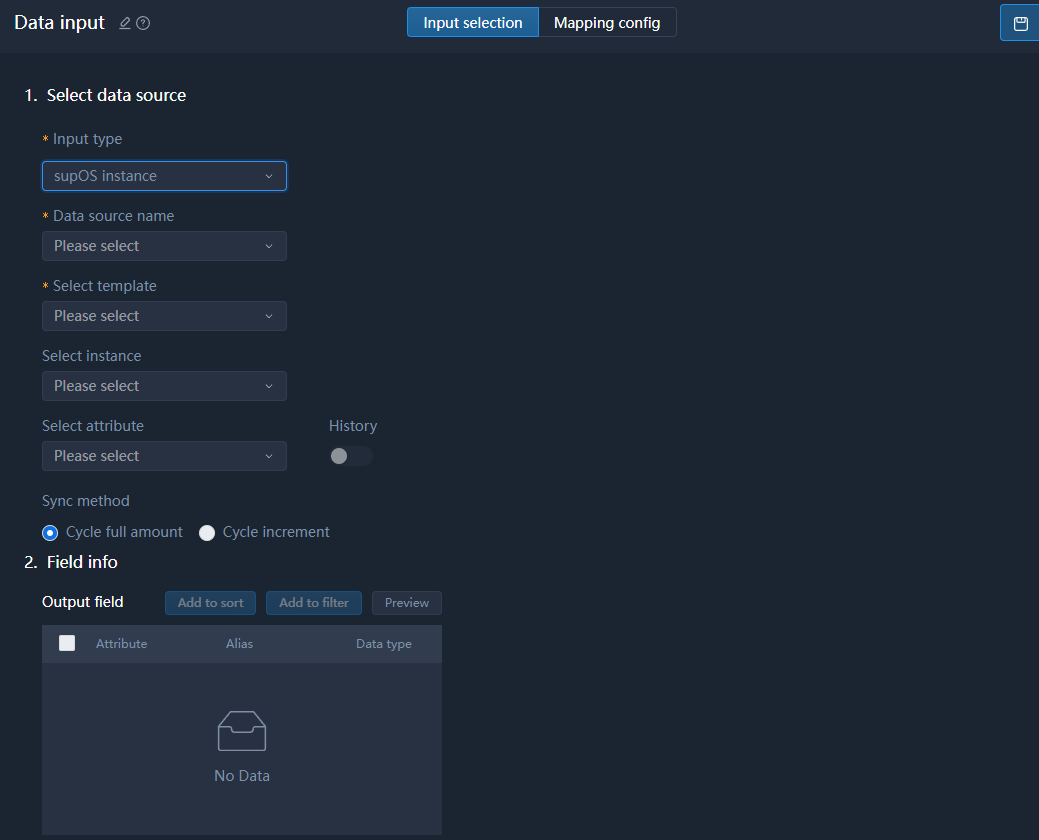
Data Input
- supOS instance
- Select template, instance, attribute from the supOS you added.
- Enable History to add attribute history information such as alias, value and time as output fields.
- File data source
- HDFS is not supported.
- Select File match under File selection method, and you can use wildcard * with suffix to match the file name. For example, test*.xlsx.
- Select File upload under File selection method, and you need to save the file in UTF-8 encoding if the file contains Chinese characters.
When the input data source is a file, the published task reads the file and output results again if the file changes.

- API data source
| Item | Description |
|---|---|
| Data source type |
|
| Request address | Enter the API request address and use #{} to identify variables. |
| Request header param | Set the header parameter of the API. When setting Variable as the Processing method, you can select the value from global variables. |

Message Queue Input
Collects data from message queue and maps it to a 2-demension table, and delivers to downstream operators for processing.
| Item | Description |
|---|---|
| Data source type | Only Kafka and RocketMQ are available. |
| Topic | Select the corresponding topic of the data to be added. You can click Data preview to view the data. |
| Field settings | Click New field to add fields corresponding to output information. |
| Initial offset |
|

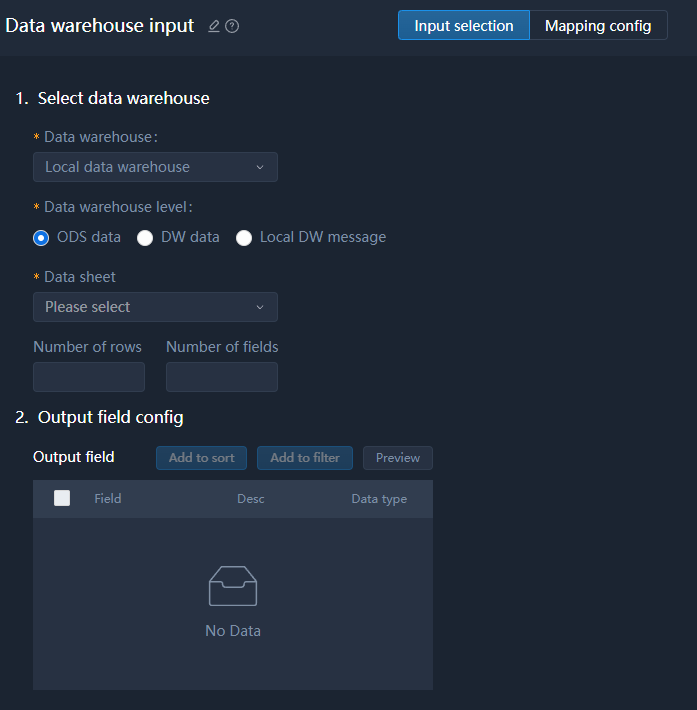
Data Warehouse Input
Supports tables and views on ODS, DW and local DW message.
Install X-DAM in advance. Otherwise, Local data warehouse will not be available.
| Item | Description |
|---|---|
| Data source type | Presently, only Local data warehouse is available with X-DAM installed. |
| Data warehouse level | Select the level of the data in data warehouse. |
| Data sheet | Select the data sheet. |
Data Processing Node
Data Quality
| QC Rule | Description |
|---|---|
| Null check | Select a field, check whether the field has null values, and select from Discard, Fix and Ignore as the subsequent operation. |
| Range check | Select a field, set a value range to filter the field and leave values only within the set range. |
| Data format check | Select a field, and use the embedded or custom expression to verify its data format. |
| Enumeration value check | Select a field, and set certain values to check whether the field value is one of the enumerated values. |

SQL Execution
Uses SQL statements to perform simple operations such as insert, delete and update on the relational data sources.

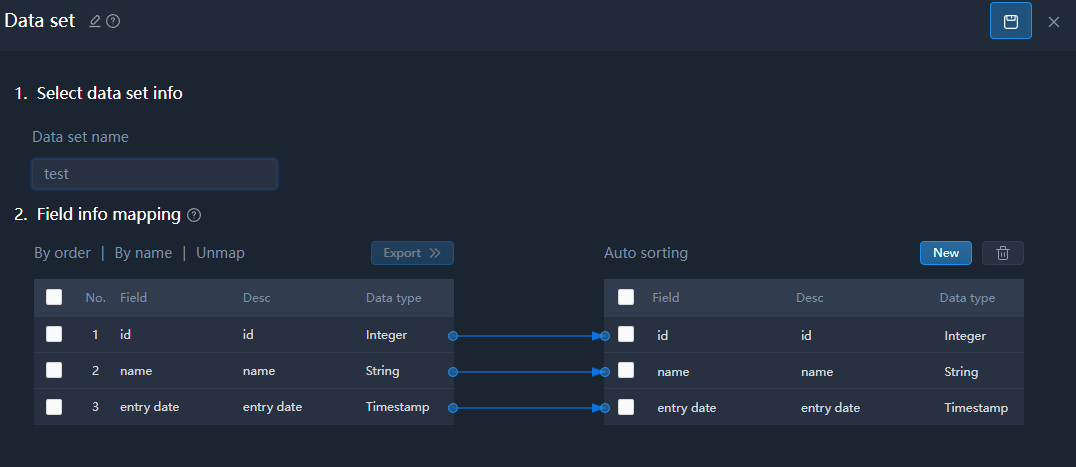
Data Set
Renames data fields or configures field mapping to generate a new dataset, mainly used for redefining the data structure set during data processing.
Data Filtering
Multiple filter conditions are available for a single field, and data that meets all conditions will be filtered.
- in/not in: For numeric fields. Value is an array of numbers and use comma to separate. in means the field value equals to one of the numbers and not in means equals to none.
- like/not like: For text type of fields. like matches part or all of the text and not like matches none.
- between/not between: For date type of fields. between means the date is within the set range and not between means not.

Data Connection
Integrates data from multiple tables into one.
- Drag 2 data input operators and configure them with 2 relational data tables.
- Drag the Data connection operator and connect both data sources to it.
- Double-click Data connection, and then configure its connection relation.
- Select data sources, and then click to select the join relation.
- Click the data source to be matched.
- Click New to add the match field.

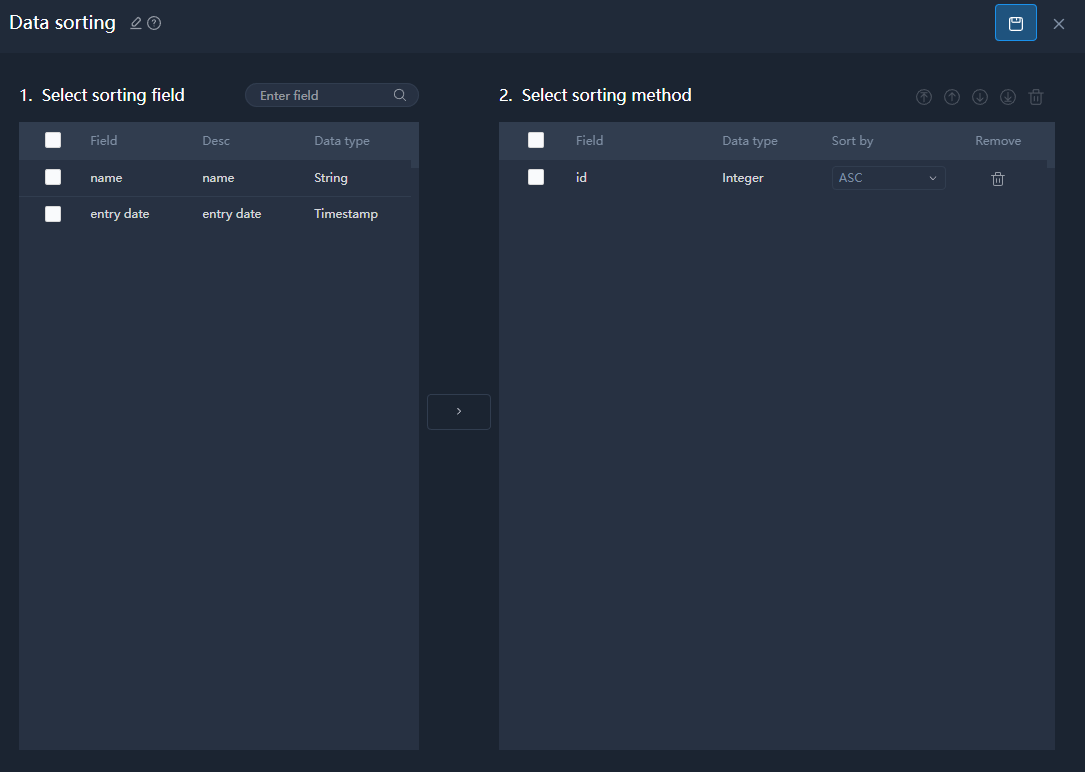
Data Sorting
The sorting priority goes down along with the field position on the list.
Data Merging
Merges data from multiple data sources. You can select columns from multiple sample sets and merge them into a data set.
- Drag 2 data input operators and configure them with 2 relational data tables.
- Drag the Data merging operator and connect both data sources to it.
- Double-click Data merging, and then configure its merging relation.
- Click New to add a merged field.
- Enter the merged field name, and then select field type and fields from both data source to be merged.

Missing Value Handling
Replaces null and empty strings in the data source to make sure subsequent data processing such as feature query, modeling, goes smoothly.
- Replaces the missing value with the maximum, minimum, average value of the column, or a constant value, global variable or linear fitting value.
- Use custom formula to generate values as replacement. Only +, -, *, / are supported.

Data Type Conversion
Converts the type of input fields.
If the conversion is not legal, 0 is generated.

Data Completion
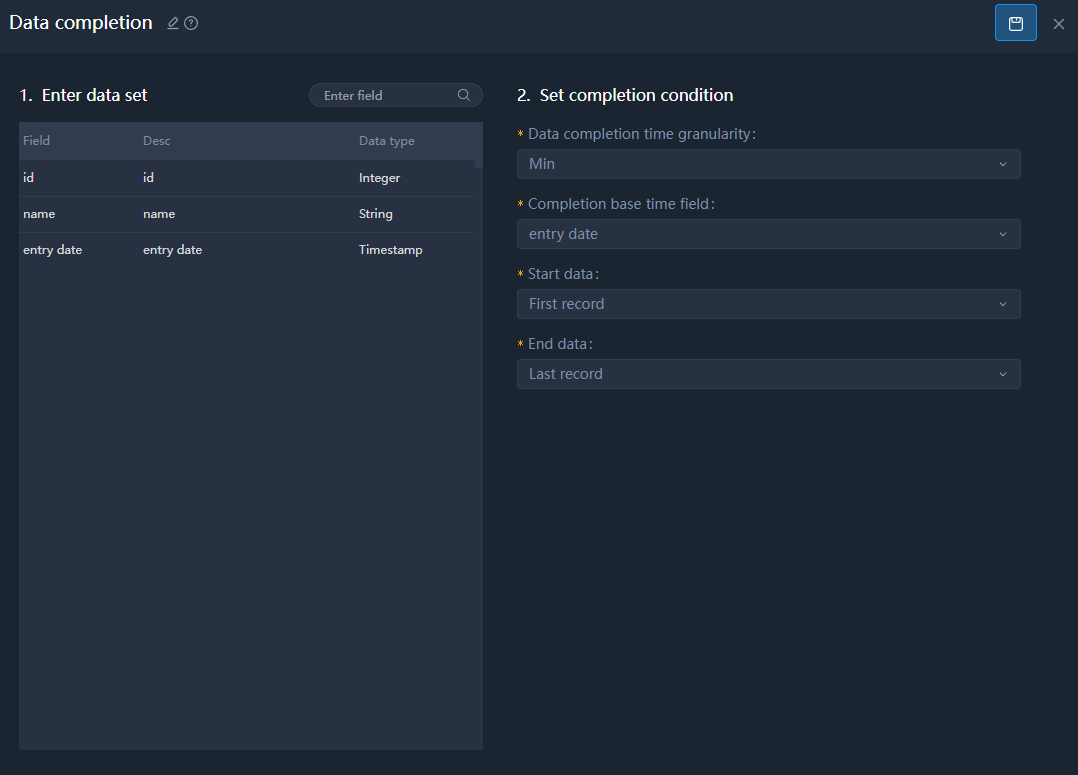
| Item | Description |
|---|---|
| Data completion time granularity | Complete data columns based on the set granularity. For example, set the granularity to Second, the complete the column where seconds are missing. |
| Completion base time field | Select a time field to be completed. |
| Start data | The data column where the completion starts. |
| End data | The data column where the completion ends. |

Variable Settings
Gives new value to global variables you set during task development. The new value can be either manually set or fields from the input data source.

Data Aggregation

Aggregate data based on the set group fields.
- Select fields, and then click Add group field. The aggregated data will be grouped by the set fields.
- Select fields of numeric type, and then click Add aggregated field to add fields to be aggregated.
- Set Aggregation cycle type.
| Item | Description |
|---|---|
| Aggregation cycle type |
|
| Aggregate base time field/Sort field | Select a base sorting field. |
| Aggregation cycle | Set the time or data record by which the aggregation is calculated. |
| Record time filling method/Record entry method | Set the output value, which can be either the initial value or end value of each cycle. |
| Sliding window | Only available when setting Aggregation cycle type to Time. |
| Additional output data record field | Only available when setting Aggregation cycle type to Data record. Select an additional field for output. |
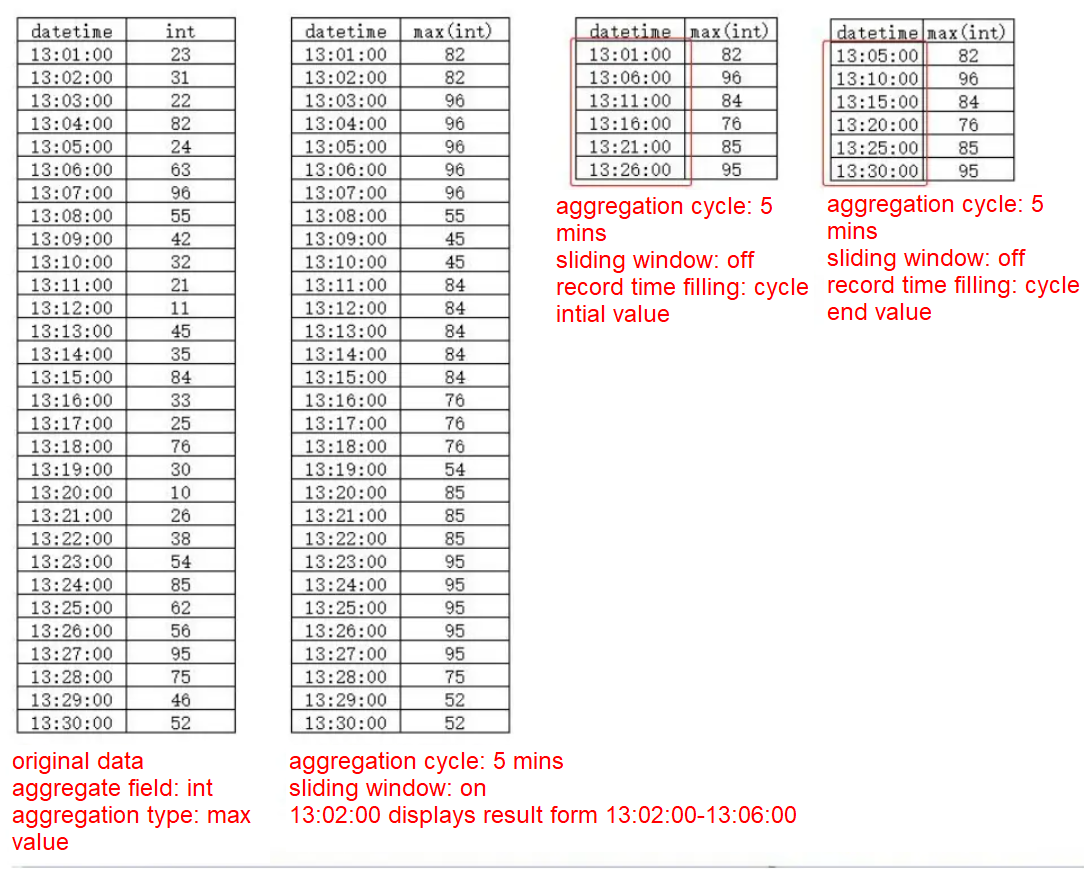
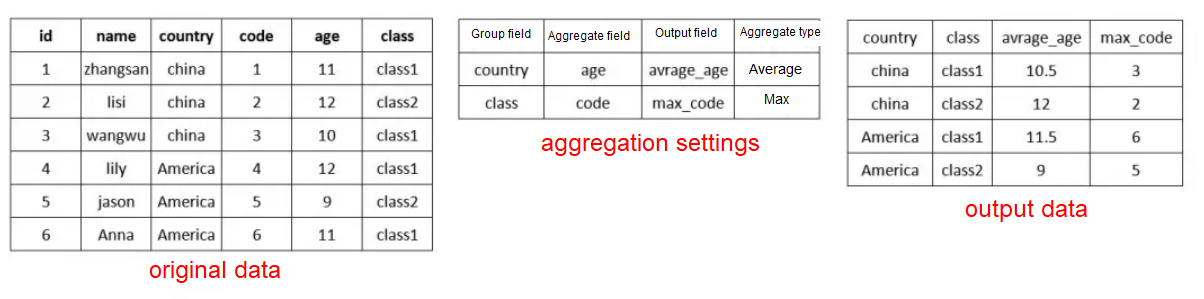
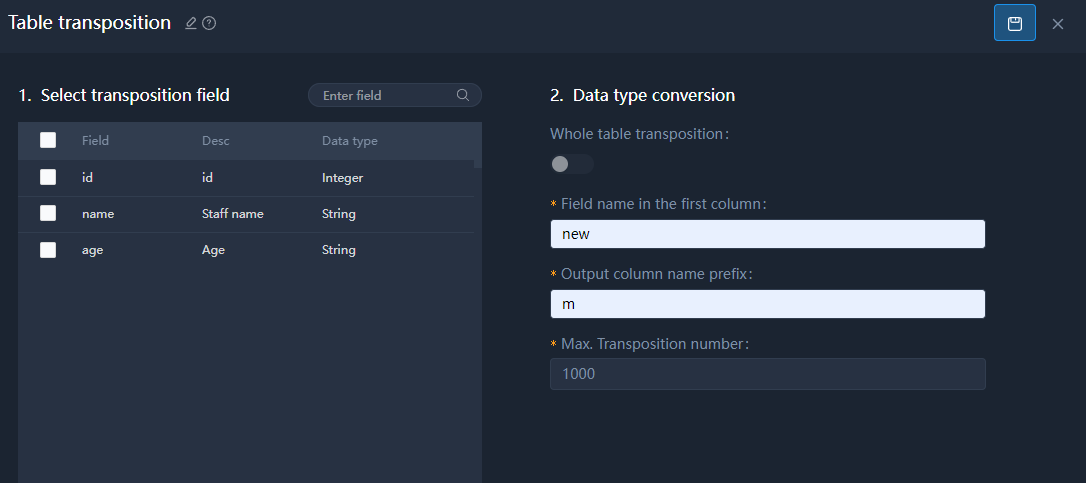
Table Transposition
Only available for file type data, and output to file type of data.

Custom Operator
You can customize algorithm and its functions.
Presently, only original JaveScript is available.
- JavaScript rules:
- The input parameter of the JS script is a collection of data passed down from the previous node, which can be a single or multiple entries.
- The definition of the data collection in the script is "dataList".
- To obtain the value of a property, use the dot notation followed by the property name (e.g., ".id").
- The JS script should return the corresponding object or data collection after performing the required operation in the form of a JSON array or string.
- The variables configured on the page can be directly used in the JS script (just ensure that the variable names match).
- Debugging logs can be added to the JS script using the "log.debug()" function, and the debugging results can be viewed at the bottom of the script.
- It is possible to use Java-related collection classes for operations within the JS script.
- Script example
var arr = [];
for (var i=0; i<dataList.length; i++) {
dataList[i].id = dataList[i].id + 10;
arr[i] = dataList[i];
}
arr;
- When calling a function with an input object, pay attention to null values that may cause a NullPointerException.
- When performing operations on input fields, be aware of the object types of the fields (comparing time objects may result in different dates appearing equal, so it is recommended to convert them to strings or primitive types before operating on them).
- When performing calculations on numerical values, the data type may change unexpectedly.
- In a JS script, custom variables cannot have the same name as global variables configured during task development.
After writing the script, click Data simulation to debug the data. You can add up to 50 records.

Debug the script to make sure the result is reasonable.

Big Data Model
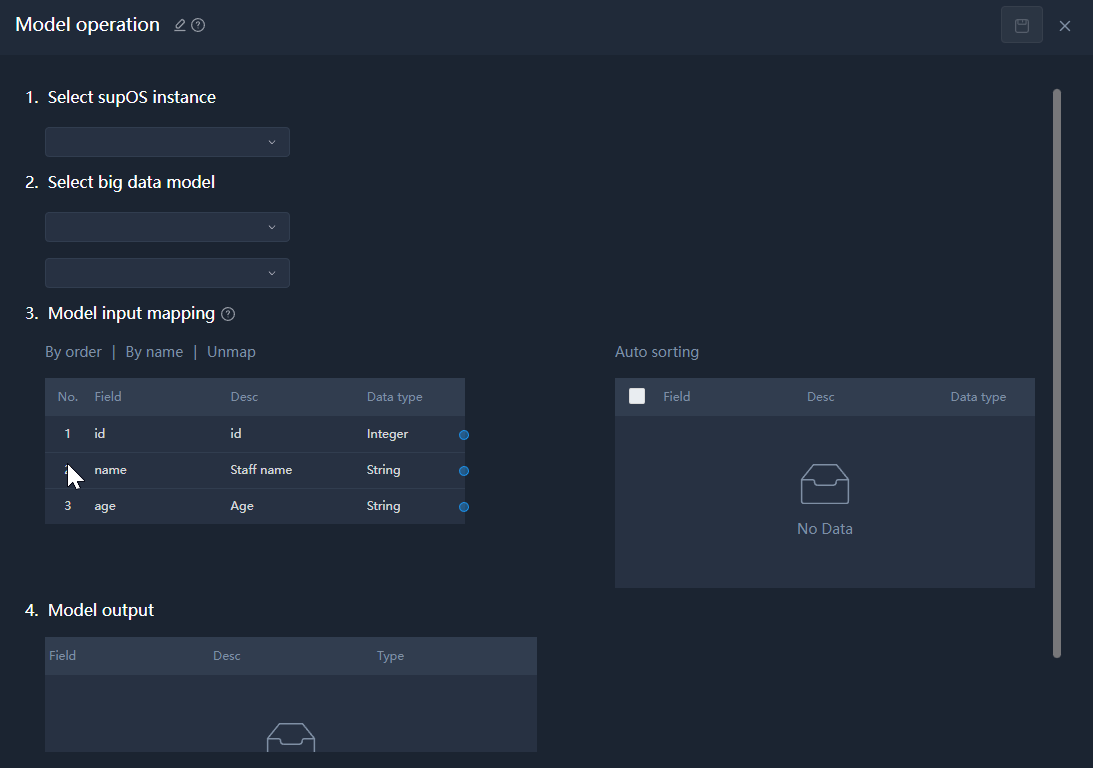
Model Operation
Runs big data model of supOS and output the results.
Model Update
Select big data models that can be updated, and update them automatically and output the results.
Generate Sample Set
Generates sample sets data and synchronizes to X-BD sample set management.
- No downstream operators.
- String type of data in sample set cannot contain English comma ,.

Process Control
Based on the set conditional statements, branch tasks that meet the conditions are executed.
- Connect multiple operators (up to five branches) after the branch task node, and then double-click the branch task to configure its parameters.
- Click Settings corresponding to each subsequent operator, and set their conditions.info
Make sure the result is boolean type of data, and only condition returns True, will the branch task be executed.

Data Desensitization
By using data desensitization to process multiple fields, the desensitized data will overwrite the original data and flow to downstream operators.

Data Output
Data Output
Configurations are similar to the input data source. For details, see Data Input Node.
- supOS instance

- File data source

- API data source

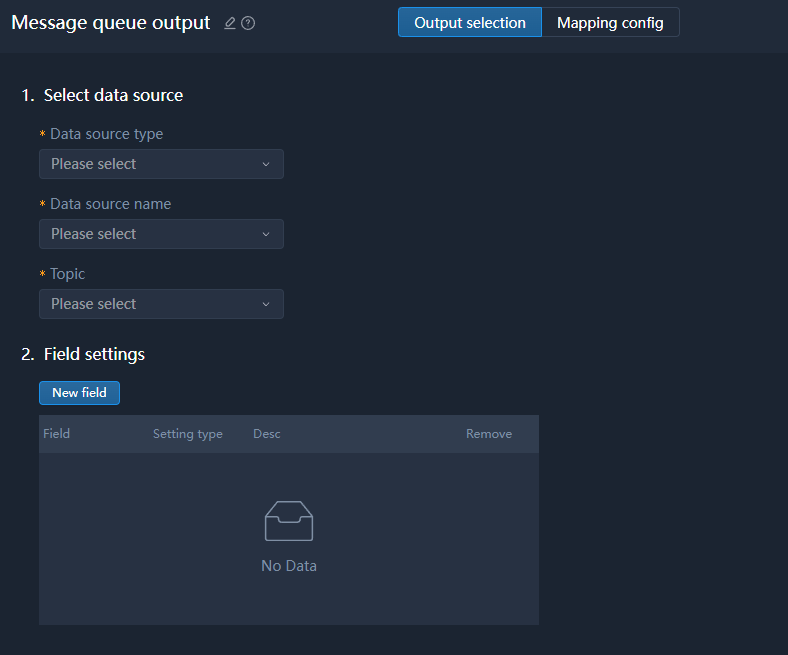
Message Queue Output
Kafka, mQTT and RocketMQ are supported.
Data Warehouse Output

HBASE Output
- HBase data source only receives string type of data.
- rowKey, as the primary key for an HBase data source, a mapping relationship must be established for it. If there are duplicate values in the data source mapped to it, only the latest row of data will be retained.
